Was Google’s document ‘leak’ a strategic move? An SEO theory

Read it again: there was no leak. The information was shared with industry veterans.
It certainly is a treasure map for SEOs. Solving this puzzle will require our collective insight, critical thinking and analysis – if that’s even possible.
Why the pessimism?
It’s like when a chef tells you the ingredients to the delicious dish you’ve just consumed. You hurry to note it all down as he turns away.
But when you try recreating the same recipe at home, it’s nowhere near what you experienced at the restaurant.
It’s the same with the Google document “leak.” My perspective is our industry was given the types of ingredients used to determine the top search results, but no one knows how it’s all put together.
Not even the brightest two among us who were given access to the documentation.
If you recall…In May, thousands of internal documents, which appear to have come from Google’s internal Content API Warehouse, claimed to have been leaked (per publication headlines).
In reality, they were shared with prominent industry SEO veterans, including Rand Fishkin, SparkToro co-founder. Fishkin outright acknowledged in his article that the information was shared with him.
In turn, he shared the documentation with Mike King, owner of iPullRank. Together and separately, they both reviewed the documentation and provided their own respective POVs in their write-ups. Hence, my take on all of this is that it’s strategic information sharing.
That fact alone made me question the purpose of sharing the internal documentation.
It seems the goal was to give it to SEO experts so they could analyze it and help the broader industry understand what Google uses as signals for ranking and assessing content quality.
“You don’t pay a plumber to bang on the pipe, you pay them for knowing where to bang.”
There’s no leak. An anonymous source wanted the information to be more broadly available.

Going back to the restaurant metaphor, we can now see all the ingredients, but we don’t know what to use, how much, when and in what sequence (?!), which leaves us to continue speculating.
The reality is we shouldn’t know.
Google Search is a product that’s part of a business owned by its parent company, Alphabet.
Do you really think they would fully disclose documentation about the inner workings of their proprietary algorithms to the world? That’s business suicide.
This is a taste.
For established SEOs, the shared Google documentation that’s now public sheds light on some of the known ranking factors, which largely haven’t changed:
- Ranking features: 2,596 modules are represented in the API documentation with 14,014 attributes.
- Existence of weighting of the factors.
- Links matter.
- Successful clicks matter.
- Brand matters (build, be known).
- Entities matter.
Here’s where things get interesting because the existence of some aspects means Google can boost or demote search results:
- SiteAuthority – Google uses it but also denied having a website authority score
- King’s article has a section called “What are Twiddlers.” While he goes on to say there’s little information about them, they’re essentially re-ranking functions or calculations.

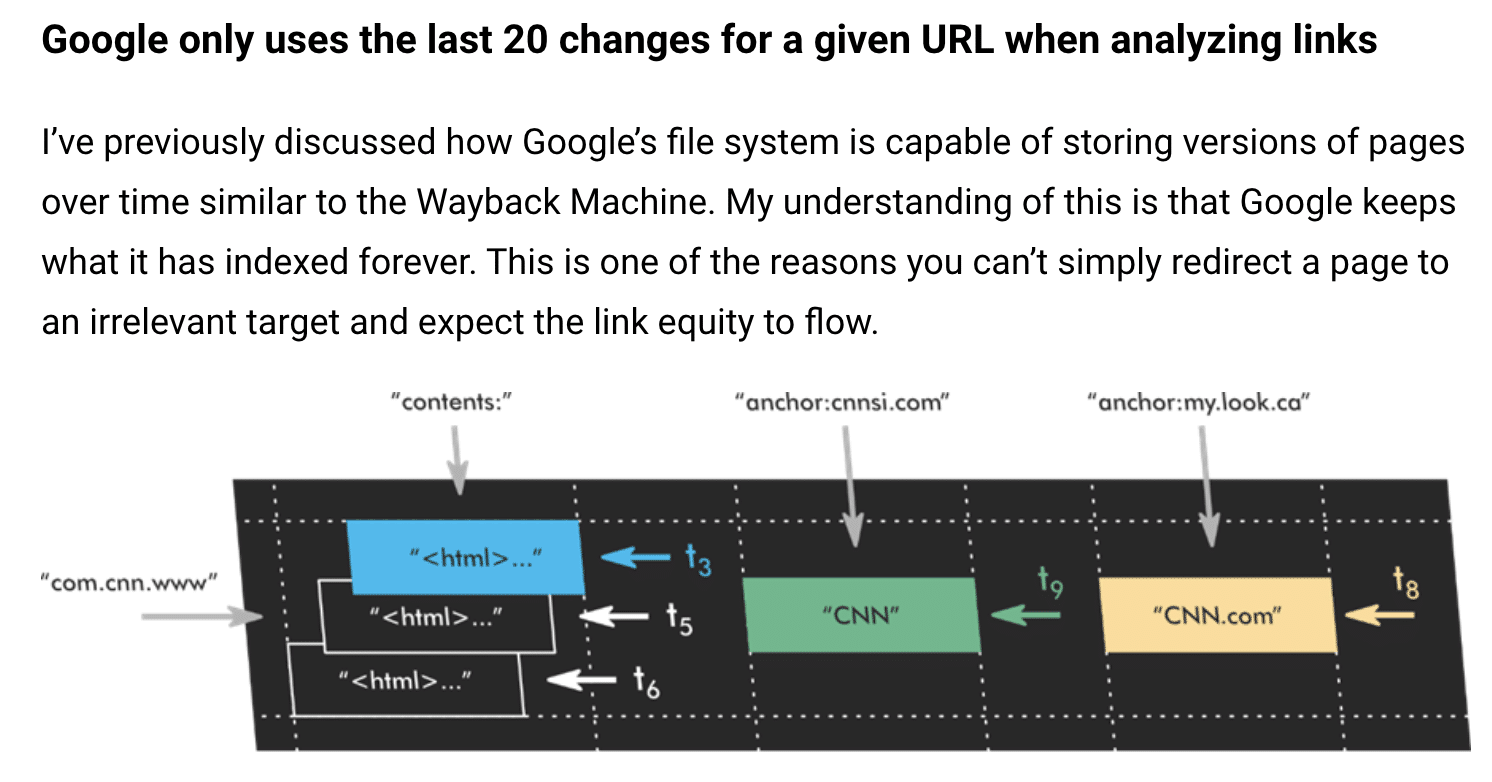
- King’s article “Google only uses the last 20 changes of a URL when analyzing links.” Again, this sheds some light on the idea that Google keeps all the changes they’ve ever seen for a page.
Both Fishkin and King’s articles are lengthy, as one might expect.
If you’re going to spend time reading through either articles or – tip of the cap to you – the documents themselves, may you be guided by this quote by Bruce Lee that inspired me:
“Absorb what is useful, discard what is not, add what is uniquely your own.”
Which is what I’ve done below.
My advice is to bookmark these articles because you’ll want to keep coming back to read through them.
Rand Fishkin’s insightsI found this part very interesting:
“After walking me through a handful of these API modules, the source explained their motivations (around transparency, holding Google to account, etc.) and their hope: that I would publish an article sharing this leak, revealing some of the many interesting pieces of data it contained and refuting some “lies” Googlers “had been spreading for years.”
The Google API Content Warehouse exists in GitHub as a repository and directory explaining various “API attributes and modules to help familiarize those working on a project with the data elements available.”
It’s a map of what exists, what was once used and is potentially currently being used.
Which ones and when is what remains open to speculation and interpretation.
Smoking gunWe should care about something like this that’s legitimate yet speculative because, as Fishkin puts it, it’s as close to a smoking gun as anything since Google’s execs testified in the DOJ trial last year.
Speaking of that testimony, much of it is corroborated and expanded on in the document leak, as King details in his post. 